


系列导航:如果你想把这组开发者文章串起来看,可以先读 APIporter 开发者接入教程导航:OpenAI Compatible、Python、Node.js、Go、PHP、Java。
为什么 APIporter 可以用 OpenAI 兼容格式调用
很多开发者第一次接触 APIporter 时,最关心的问题不是“它能不能用”,而是“应该按什么格式接”。如果你之前接过 OpenAI 兼容接口,那这件事其实非常直接:APIporter 底层就是 NewAPI 路线,对大多数开发工具、SDK 和脚本来说,优先按 OpenAI Compatible / OpenAI 兼容接口 来接,通常就是最稳的方案。
这篇文章就不讲客户端界面怎么点,而是专门面向开发者,说明如何用 OpenAI 兼容格式直接调用 APIporter,包括请求地址、鉴权方式、消息结构、模型切换思路以及常见报错排查。
接入前需要准备什么
正式调用前,建议先准备好下面这些信息:
- APIporter 官网:https://www.apiporter.com
- API Key:登录 APIporter 后台获取
- Base URL:以 APIporter 后台或文档给出的真实接口地址为准
- 模型名称:以 APIporter 当前支持列表为准
这里有个最容易搞混的点:官网地址不是接口地址。你在代码里真正要填的,是 APIporter 提供的 API 请求地址,而不是官网首页,也不是控制台页面地址。
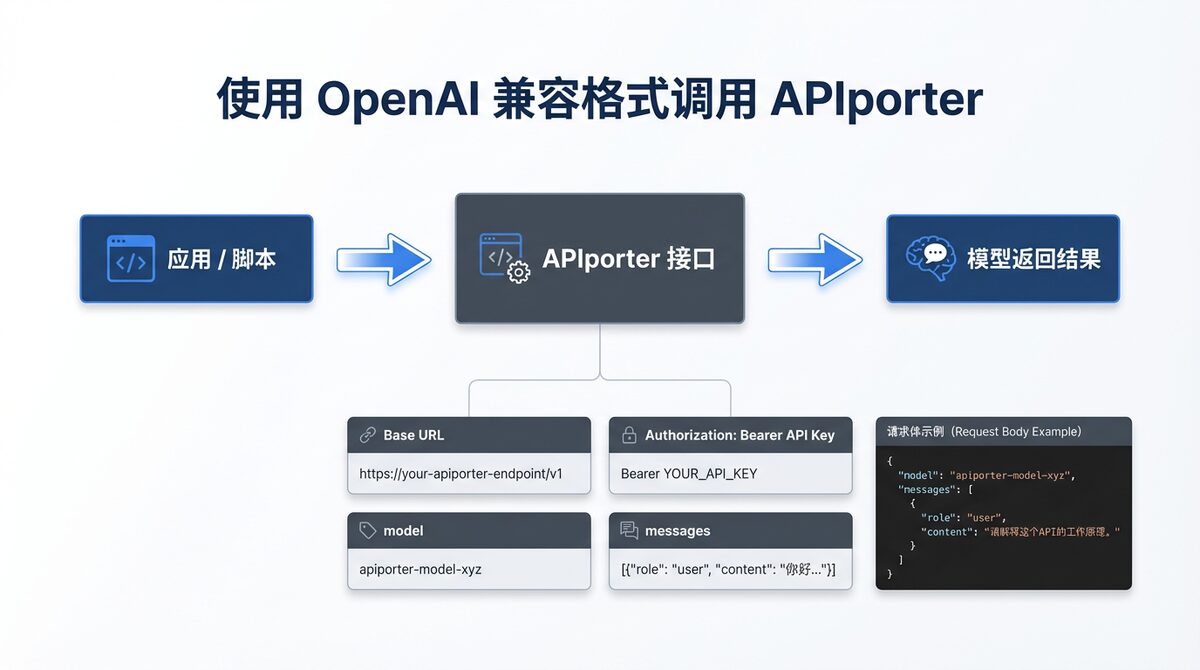
OpenAI 兼容调用的核心结构
如果你接过 OpenAI 兼容接口,整体结构其实非常熟悉,通常就包括这几个要素:
- Authorization:用 Bearer Token 传 API Key
- Base URL:填写 APIporter 的真实接口地址
- model:填写要调用的模型名称
- messages:按 OpenAI 常见消息格式传用户输入
最常见的调用方式,一般就是向聊天接口发送一个 POST 请求,消息结构形如:
{
"model": "这里填写 APIporter 支持的模型名",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
]
}真正发请求时,只要你的接口地址、鉴权方式和模型名都写对,大多数兼容 OpenAI 的程序就能正常跑通。
一个最基础的 HTTP 请求示例
如果你想先不依赖任何 SDK,直接验证接口是否能通,可以先用最基础的 HTTP 请求思路测试。下面这个示例是最容易看懂的版本:
POST {APIporter 提供的真实接口地址}
Authorization: Bearer 你的 API Key
Content-Type: application/json
{
"model": "这里填写 APIporter 支持的模型名",
"messages": [
{
"role": "user",
"content": "请用一句话说明 OpenAI 兼容接口的作用"
}
]
}只要返回里能正常拿到模型输出内容,就说明你的 OpenAI 兼容调用已经跑通。
如何在代码里组织 Base URL、API Key 和模型名
从工程角度看,最稳的做法不是把参数写死在代码里,而是把这三个核心变量拆出来:
- BASE_URL:APIporter 的接口地址
- API_KEY:APIporter 的密钥
- MODEL_NAME:当前要调用的模型
这样做的好处很明显:
- 后续切换环境更方便
- 切换模型时不用改主逻辑
- 更适合做多模型实验和统一配置
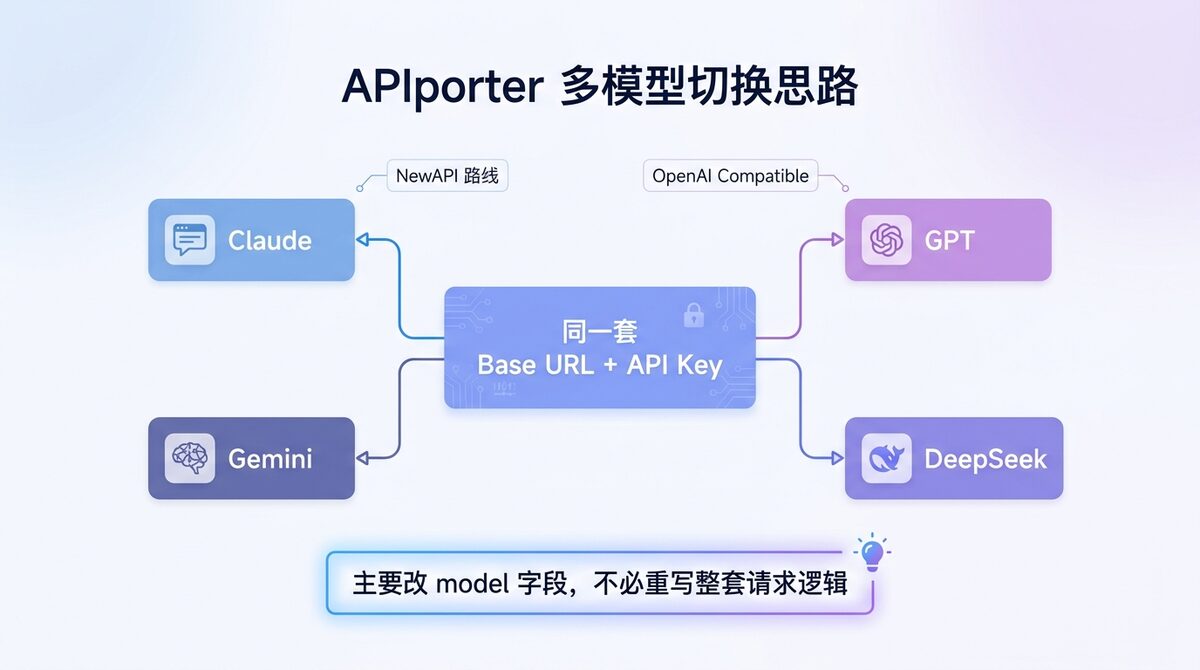
比如你完全可以把模型名单独写成变量,在 Claude、GPT、Gemini、DeepSeek 之间切换时,只改一行配置,而不必重写整套请求逻辑。
如何切换 Claude / GPT / Gemini / DeepSeek 模型
很多开发者接 APIporter,不是只想调用单一模型,而是想在不同模型之间快速切换。按 OpenAI 兼容方式接入时,最核心的切换点通常只有一个:model 字段。
也就是说,只要 APIporter 当前支持这些模型,你在代码层通常只需要:
- 保持同一套 Base URL
- 保持同一套鉴权方式
- 把
model改成目标模型名称
例如你的项目里可以这样理解:
当前模型 = Claude
切换后模型 = GPT
再切换后模型 = Gemini
或者切换为 DeepSeek真正写代码时,关键不是“模型大类名字”,而是 APIporter 当前支持列表里的准确模型 ID。如果你自己随手简写,很容易出现请求发出去了,但模型名不被识别的情况。
最常见的接入错误有哪些
开发者第一次接 APIporter 时,最容易踩的坑通常就是下面这几类:
一、把官网地址当成接口地址。
这是最常见的错误。官网是官网,控制台是控制台,API 请求地址是 API 请求地址,这三者不能混。
二、API Key 前后有空格,或者复制不完整。
表面上看起来已经填了 Key,实际上多一个空格就可能导致鉴权失败。
三、模型名称写错。
模型必须以 APIporter 当前支持列表为准,不能自己拍脑袋写简称。
四、代码逻辑没问题,但 SDK 基础地址没改。
很多人改了 Key,没改 Base URL,结果请求还是发到默认服务商去了。
五、以为不同模型就要换不同接口协议。
对于 APIporter 这种 OpenAI 兼容路线,通常切模型主要改的是 model,而不是整套调用协议。
什么时候适合先用 OpenAI 兼容格式打底
如果你后面还要写 Python、Node.js、Java、PHP、Go 等不同语言版本,那最推荐的做法就是先把 OpenAI 兼容调用逻辑跑通,再拆成各语言示例。
因为这一层相当于整个开发者教程矩阵的基础:
- 它先讲清楚 APIporter 的接入思路
- 它能统一 Base URL / API Key / model 的理解
- 它能把后面的语言教程都建立在同一个标准上
换句话说,先把 OpenAI 兼容格式说明白,后面的 Python、Node.js、Java、PHP、Go 文章就都更容易写,也更不容易前后口径打架。
总结
如果你想从开发者视角快速接入 APIporter,最稳的路线就是:按 OpenAI 兼容格式接。准备好 API Key、真实 Base URL 和准确模型名之后,用标准的消息结构发起请求,就可以把大多数调用场景先跑通。
对于 APIporter 这种底层就是 NewAPI 的服务来说,这条路也是最适合做多语言教程和多模型切换的基础方案。后面无论你继续接 Python、Node.js、Java、PHP 还是 Go,本质上都还是围绕这套兼容结构展开。







