为什么“备份成功”不等于“可以恢复”
很多人第一次做数据库运维,最容易踩的坑就是:看到备份脚本每天正常执行、目录里也有 .sql 或压缩包,就默认这件事已经稳了。可真到业务出故障、表被误删、系统被误操作时,才发现文件虽然在,恢复却并不顺利。常见问题包括备份文件不完整、导出时锁表导致数据不一致、备份里缺少存储过程和触发器,甚至压缩包本身已经损坏。对业务来说,备份从来不是“有没有文件”,而是“能不能在需要的时候把服务拉回来”。
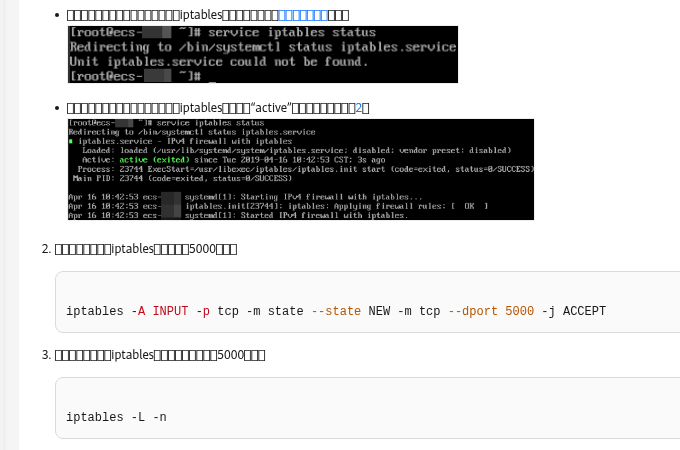
真正危险的,往往不是没备份,而是没演练
现实场景里,这种事情特别常见。比如一台 MySQL 服务器每天凌晨自动执行 mysqldump,日志看起来全绿,结果某天运营误删了订单表,运维拿备份去恢复时才发现导出脚本里漏掉了一个库;又或者备份恢复到了测试机,能导入,但应用一连接就报字符集错误。更麻烦的是,有些团队备份只做“全量留档”,却从没测过恢复耗时。平时觉得自己很安全,真出事故时,才发现恢复 200G 数据要几个小时,前台业务根本等不起。
一套靠谱的备份方案,至少要回答 3 个问题
第一,备份的是什么:是整库、单表,还是连账号权限、配置文件一起打包?第二,备份放在哪里:本机、异机,还是对象存储?只放在原服务器上,一旦磁盘坏了,备份等于一起没了。第三,多久能恢复:这是很多小团队最容易忽略的点。技术上常说 RPO 和 RTO,简单理解就是“最多能丢多少数据”和“业务多久能恢复”。如果你的站点一天成交几百单,那就不能接受只保留前一天夜里的备份;如果是内部系统,也许每天一次就够。备份策略一定要跟业务容忍度匹配,不能只图省事。
恢复演练到底怎么做,才不算走过场

最实用的做法,是每隔一段时间找一台测试环境,按真实故障流程走一遍:先拿最近一次备份恢复数据库,再让应用连上去,检查表结构、关键数据、账号权限和程序读写是否正常。别只停留在“命令执行成功”这一步,要像线上出事一样验证。比如抽查最近 10 条订单、登录记录、配置项有没有丢;如果用了主从或增量日志,也要确认时间点恢复是否可行。演练时顺手把步骤记录下来,谁来恢复、先做什么、需要多长时间,写清楚以后,真正出问题时才不会一群人围着服务器发呆。
小团队也能立刻补上的 4 个动作
如果你现在手里就有业务库,今天就可以先做四件事:第一,检查备份文件是否真的能打开、能导入;第二,把备份至少再存一份到异机或对象存储;第三,给备份任务加结果告警,不要只看脚本退出码;第四,本周内做一次恢复演练,哪怕先拿测试库试一次都比没有强。数据库备份最怕的不是花钱,而是“以为自己做了”。等事故来了才验证,成本往往比平时多做一步高得多。对运维来说,真正有价值的备份,不是安慰自己的那份文件,而是出事后能把业务稳稳救回来的那套流程。