
最新发布第17页
排序

服务已经启动,为什么外部还是访问不了?从监听地址到安全组逐层排查
服务已经启动但外部仍访问不了,不一定是程序崩了。本文按监听地址、本机可达、防火墙、安全组、反向代理和日志证据,梳理一套可复用的端口访问排查顺序。

买服务器时,为什么不能先只看价格?
服务器选型与网络质量相关示意图 为什么很多人一开始会先盯着价格看? 第一次买服务器的人,最容易先问的一句话通常不是“我的业务需要什么配置”,而是“有没有更便宜的”。这种思路非常常见,...

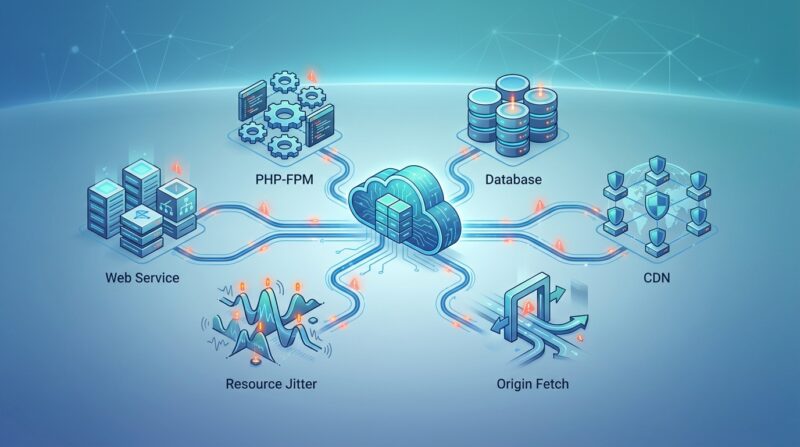
为什么网站会偶发 502 / 504?先查哪里?
为什么网站会偶发 502 / 504?先查哪里? 网站出现 502 或 504,是很多站长最头疼的一类问题。因为它和“完全打不开”不一样,也和“纯粹变慢”不完全一样。最烦的地方在于,这类错误经常是偶发...

50万师生接入ChatGPT后,教育AI开始从工具试用走向制度考题
ChatGPT Edu进入超50万师生校园场景,国内AI应用在高考期间收缩拍题和作文能力,教育AI正在从工具试用走向制度化治理。

GPT-5.5-Cyber上线后,AI安全竞争开始回到工程治理
OpenAI推出GPT-5.5-Cyber与Codex Security插件,同时Codex日志写入问题暴露AI开发工具链风险。AI安全竞争正在从模型能力走向可审计、可回滚、可治理的系统工程。

















