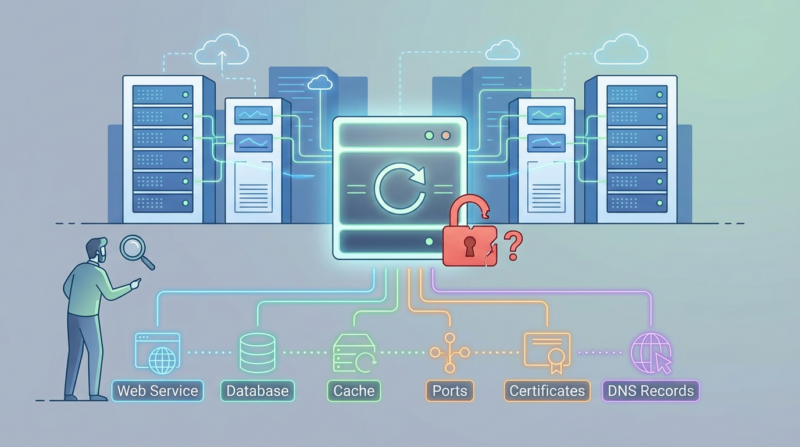

为什么服务器明明已经重启了,网站却还是打不开?
很多人遇到网站故障时,第一反应就是先重启服务器。这个动作并不奇怪,因为它简单、直接,而且有时候确实能暂时缓解问题。但真正让人头疼的是另一种情况:服务器已经重启成功,系统也能登录,SSH 也正常,结果网站还是打不开。首页打不开、后台进不去、浏览器一直转圈,甚至直接报 502、504、连接失败。到了这一步,很多人会开始发懵:服务器都起来了,为什么网站还没起来?
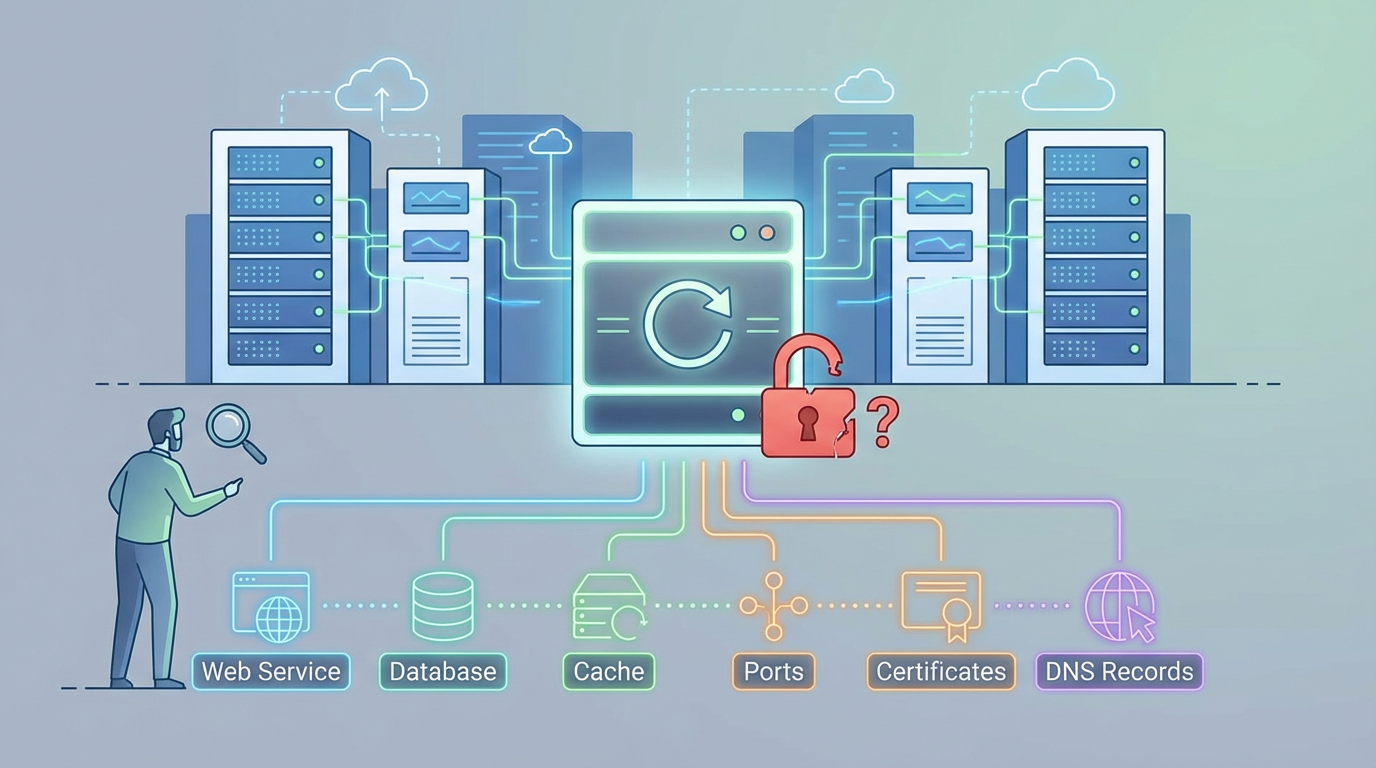
问题就在于,“服务器重启成功”并不等于“网站服务链路已经全部恢复”。网站能不能打开,至少还要看 Web 服务、数据库、程序运行环境、端口监听、解析指向、证书状态、缓存和安全策略这些层级有没有一起恢复。也就是说,重启服务器只是把机器重新拉起来,但不代表站点本身就一定跟着恢复正常。
第一步:先确认到底是服务器起来了,还是只有系统起来了
很多人重启完服务器之后,只要还能 SSH 登录,就会默认一切都恢复正常。但这其实只能说明操作系统已经起来了,并不能说明网站服务也已经跟着起来。因为对网站来说,真正关键的不是“能不能登录服务器”,而是 Nginx / Apache、PHP、MySQL、Redis、站点程序这些依赖有没有一起恢复。
所以重启之后的第一步,不是先刷新浏览器,而是先确认 Web 服务、数据库和相关运行环境是否都在工作状态。很多“重启后网站还是打不开”的问题,根本不是服务器没起来,而是某一个关键服务压根没有正常启动。
第二步:最先检查 Web 服务是不是启动失败了
服务器重启后网站打不开,最常见的原因之一,就是 Web 服务没有跟着正常起来。比如 Nginx 配置有误、端口冲突、证书路径错误、站点配置文件损坏,这些都可能导致服务器虽然已经重启成功,但 Nginx / Apache 实际并没有正常监听 80 或 443 端口。
这种情况下,用户看到的就是网站完全打不开,而服务器本身却看起来一切正常。最稳的做法是先看服务状态,再看错误日志。只要 Web 服务启动失败,通常日志里都会留下比较明确的线索,比如配置语法错误、证书加载失败、端口被占用之类的问题。
第三步:数据库没起来,前台一样会表现成“网站打不开”
除了 Web 服务之外,数据库也是重启后最容易掉链子的一层。尤其是 WordPress、商城、论坛、CMS 站点,只要 MySQL / MariaDB 没有正常起来,前台页面就可能直接打不开,或者表现成 500、连接异常、空白页、后台无法登录。用户表面上看到的是“网站没恢复”,本质上是数据库没正常接上。
有时候数据库服务不是完全没起来,而是启动特别慢、恢复过程中卡住,或者因为磁盘空间、损坏表、权限问题、异常关闭后修复时间过长,导致前台在一段时间里看起来像彻底挂掉。这个时候如果只盯着浏览器刷新,是看不出问题在哪的,必须回到数据库服务状态和日志去看。
第四步:程序环境或缓存层没恢复,也会让网站看起来像坏了
网站能不能打开,不只是 Web 服务和数据库两件事。很多站点还依赖 PHP-FPM、Redis、Memcached、队列服务、计划任务或者对象缓存。如果这些环境在服务器重启后没有一起恢复,网站一样可能表现成打不开、空白页、后台卡住或部分页面异常。
尤其是带缓存的网站,重启之后如果缓存层状态异常、配置丢失或者连接失败,前台和后台都可能明显不正常。更麻烦的是,这类问题不像 Nginx 那样一眼就能看出服务没起来,而是表现成“有时候能进、有时候又不行”,更容易误导排查方向。
第五步:别忘了看磁盘、端口和证书
服务器重启之后网站打不开,还有几个特别实际但很容易漏掉的点:磁盘是不是满了、80/443 端口是不是正常监听、SSL 证书路径有没有异常、证书文件权限有没有问题。如果磁盘满了,很多服务会启动失败;如果端口没监听,外部自然打不开;如果 HTTPS 证书加载失败,Nginx 也可能直接起不来。
这也是为什么很多人明明看到服务器已经启动,却还是打不开站点。因为他们检查的是“服务器活着没”,但真正出问题的往往是“网站入口有没有正常对外提供服务”。这两个层级不是一回事。
第六步:域名解析和 CDN 也可能让你误以为“重启没恢复”
还有一种情况,是服务器其实已经恢复了,但域名解析、CDN 节点缓存或安全策略没有同步正常,结果导致用户访问时还是打到旧状态、错误节点或者缓存异常页面。这时候你在服务器上看,好像服务已经恢复;用户从外部打开,却还是显示失败。表面上像“重启没用”,实际上问题已经不在服务器本身,而是在访问入口这一层。
如果站点接了 CDN、做过解析切换、最近动过域名或证书,这一步一定不能省。尤其是外部用户反馈打不开,而你自己在服务器本机或内网里看却正常时,更要优先怀疑解析和 CDN 缓存,而不是继续机械重启。
如果网站长期对稳定性敏感,就不能只靠“出事重启”解决
很多站点之所以会反复出现“重启之后还是打不开”的情况,本质上不是不会重启,而是服务链路本身就不够稳。比如网站既要面向国内或亚洲访问,又要兼顾后台操作流畅度,这种场景下光靠重启是治标不治本,服务器本身的线路、稳定性和整体定位也要跟上。
如果你的站点比较在意访问稳定性和后台体感,像速维云的香港精品大带宽云服务器会更适合长期网站场景;如果只是测试环境、轻量项目或起步阶段的小站,速维云的香港轻量云服务器也能先把站点跑起来。关键不是出了问题一味重启,而是先把网站真正依赖的服务链条看清楚。
更稳的排查顺序,应该怎么记?
如果你遇到“服务器重启后网站还是打不开”的情况,最稳的顺序通常是这样:先确认 Web 服务是否正常启动;再确认数据库是否恢复;然后检查 PHP / 缓存 / 运行环境;接着看磁盘、端口和证书;最后补查域名解析、CDN 和安全策略。只要按这个顺序排,大多数问题其实都能比较快定位出来。
最怕的不是故障本身,而是还没分清问题在哪一层,就反复重启、反复刷新、反复怀疑程序。那样往往只会把问题拖得更久。
结语:服务器起来了,不等于网站就已经恢复
“服务器重启成功”只是网站恢复过程里的第一步,不是最后一步。网站真正能不能打开,取决于 Web 服务、数据库、运行环境、端口、证书、解析和缓存这些层级有没有一起正常工作。只要其中有一层没起来,用户看到的结果就还是“网站打不开”。
所以遇到这种情况,最稳的处理方式不是继续机械重启,而是先按服务链路一层层确认。只有把“机器起来了”和“站点恢复了”这两件事彻底分开,你后面的排查才不会一直绕圈子。











