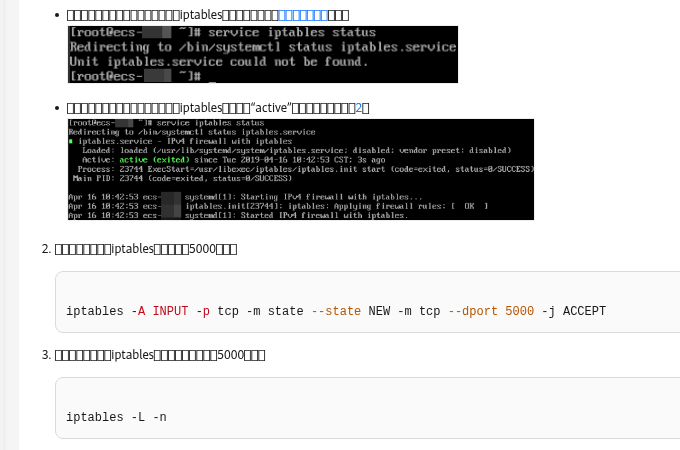

先判断是不是文件句柄耗尽
线上服务突然报错,日志里出现 Too many open files、EMFILE、accept: too many open files 之类提示时,很多人第一反应是重启服务。重启确实可能让故障暂时消失,但如果不查清楚文件句柄为什么被耗尽,下一轮流量上来、连接积压或日志轮转异常时,问题还会回来。
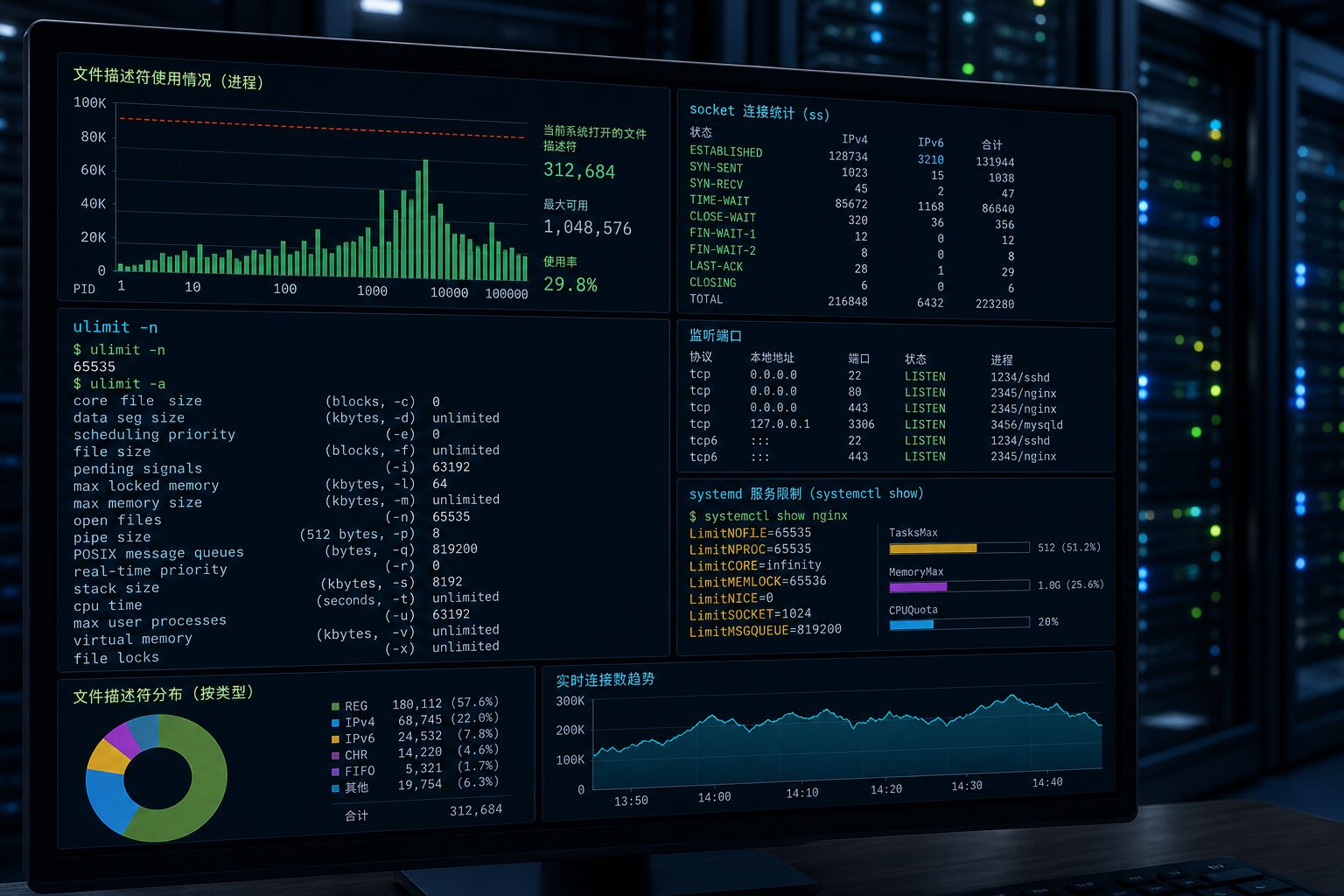
Linux 里的“文件”不只是真正的磁盘文件,网络连接、管道、socket、epoll 实例、日志文件、临时文件都可能占用文件描述符。Web 服务、数据库、缓存、反向代理、长连接网关都依赖这些描述符处理请求。当进程打开的描述符数量超过限制,新连接可能无法建立,新文件可能无法写入,服务看起来就像“突然卡死”或“部分功能不可用”。
先看系统级和进程级限制
排查第一步不是直接改配置,而是确认限制在哪一层。可以先看系统总量:cat /proc/sys/fs/file-nr。输出通常包含已分配、未使用和最大文件句柄数,重点看第一个数字是否长期接近第三个数字。如果系统级总量没有逼近上限,问题多半在单个服务进程自己的限制。
进程级限制可以通过 cat /proc/<pid>/limits 查看,重点关注 Max open files。如果服务日志持续出现 Too many open files,而这里的 soft limit 只有 1024 或 4096,那么即使服务器 CPU、内存、磁盘都很空,进程也可能因为描述符不够而拒绝新请求。
定位到底是谁打开了太多文件
确认限制后,要找出真正占用文件描述符的进程。常用命令是 ls /proc/<pid>/fd | wc -l,它能快速看到某个进程当前打开了多少描述符。如果不知道哪个进程可疑,可以结合 lsof、ss -s、ps 来看连接数和进程列表。
例如 Nginx、PHP-FPM、Java 服务、Node.js 服务或数据库连接池都可能成为高占用对象。若某个进程 fd 数持续上涨且不回落,要怀疑连接未释放、代码泄漏、日志文件未正确关闭、客户端长连接异常或上游服务阻塞。只把 ulimit 调大,可能会把故障从“很快暴露”拖成“更晚暴露、影响更大”。
区分正常高并发和异常泄漏
文件句柄多不一定就是故障。高并发网站、WebSocket 服务、消息队列消费者、反向代理节点本来就会维持较多连接。关键要看它是否和业务流量同步变化:流量上来时升高,流量下降后回落,这是相对正常的;如果流量平稳但 fd 数不断增长,或服务空闲后仍长期不下降,就要重点查泄漏。
可以把 fd 数、连接状态、QPS、错误率、内存占用一起看。比如 ss -ant | awk '{print $1}' | sort | uniq -c 能粗略观察 TCP 状态分布。如果大量连接停在 CLOSE_WAIT,常见原因是应用没有正确关闭 socket;如果大量 TIME_WAIT,则要结合短连接、反向代理、内核参数和应用连接复用一起分析。
正确调整 ulimit 与 systemd 限制
如果确认业务确实需要更高文件描述符上限,就要把限制改在服务真正生效的位置。临时命令行里的 ulimit -n 65535 只影响当前 shell 及其子进程,对已经由 systemd 启动的服务通常没有效果。很多“明明改了 ulimit 还是不生效”的问题,就卡在这里。
systemd 管理的服务应在 unit 文件或 override 里设置 LimitNOFILE=65535,然后执行 systemctl daemon-reload 并重启对应服务。用户会话类限制则可能涉及 /etc/security/limits.conf、PAM 配置和登录方式。修改后不要只看配置文件,要再次读取 /proc/<pid>/limits,确认新进程看到的限制确实变了。
别忽略应用连接池和日志策略
很多文件句柄问题不是 Linux 单点配置造成的,而是应用连接池和日志策略放大出来的。数据库连接池最大连接数设置过高、HTTP 客户端没有复用连接、对象存储 SDK 重试过多、日志切割后旧文件句柄没有释放,都可能让 fd 数持续攀升。尤其是多进程模型下,每个 worker 都有自己的限制和连接池,总量要按 worker 数量叠加估算。
如果业务部署在云服务器上,也要把系统参数、服务进程数、代理层连接数放在一起规划。比如使用 速维云 部署企业网站或业务系统时,服务器配置只是基础,Nginx、应用进程、数据库连接池和监控告警同样需要按访问规模配置,不能只看 CPU 和内存余量。
建议的排查顺序
遇到 Too many open files,可以按这条线排查:先确认报错进程;再看 /proc/<pid>/limits;接着统计 /proc/<pid>/fd 数量;然后用 lsof 或 ss 判断是文件、socket 还是日志占用;最后再决定是调高限制、优化连接池、修复泄漏,还是增加服务实例。
处理完成后,最好把 fd 使用量加入监控。单次故障修复只能解决眼前问题,持续监控才能发现趋势。一个健康的线上系统,不是永远不会触碰限制,而是在接近限制前就能看到告警,并且知道该从系统、服务还是业务代码哪一层下手。