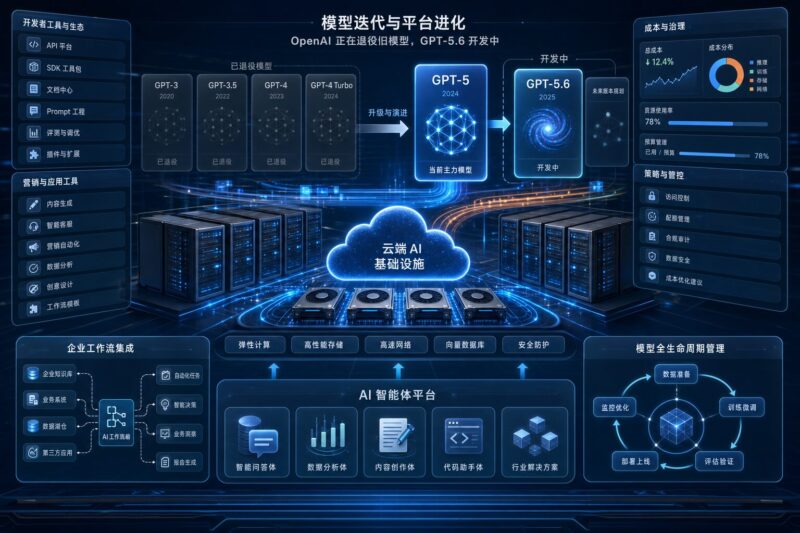

OpenAI 一边宣布 o3 和 GPT-4.5 在 ChatGPT 中进入退役倒计时,一边把更多资源推向 GPT-5.6;同一天,Anthropic 的包月折扣争议、美团 GEO 营销系统、阿里 Cloud Agents、百炼 CLI、以及 Claw Agent 训练评测框架接连出现。几条消息放在一起看,大模型行业的重心正在发生明显变化:厂商不再只拼“谁发布了一个更强模型”,而是在加速淘汰旧能力、重排价格体系,并把 Agent 推进本地生活、企业系统和开发者工具链。
这对用户和企业都很现实。模型退役意味着产品稳定性、迁移计划和 API 兼容性要重新评估;包月折扣减少意味着重度使用者开始认真算账;平台级 Agent 进入营销、跑腿、代码和企业流程,则说明 AI 应用正在从“能聊”走向“能接活”。行业竞争不再只是榜单分数,而是模型生命周期、成本治理、分发入口和落地场景的综合较量。
旧模型退场
OpenAI 宣布 o3 将于 2026 年 8 月 26 日从 ChatGPT 退役,GPT-4.5 则将在 6 月 27 日退出 ChatGPT 使用场景,仅 API 仍可继续调用。对普通用户来说,这看起来像一次版本清理;但从产品运营角度看,它其实是大模型平台进入成熟期后的必然动作:当新模型足够覆盖旧模型的大部分任务时,继续维护多套体验、计费、路由和安全策略,会让平台成本和产品复杂度迅速上升。
更关键的是,OpenAI 同时把 GPT-5.6 的开发推进到更核心位置,内部已有更强检查点上线。这意味着模型产品正在从“发布即主角”变成“持续迭代、持续替换”的服务体系。用户过去习惯把某个模型当成稳定工具,现在则要接受一个现实:模型名称、能力边界、调用成本和可用入口都可能快速变化,企业如果把关键流程绑定在单一模型上,就必须提前设计替代方案。
这类退役安排也会影响开发者生态。很多应用在提示词、评测集、工具调用和风格输出上都针对特定模型做过优化,一旦 ChatGPT 端不可用,用户体验可能变得不一致。API 仍可用只能解决一部分问题,因为大多数非技术用户依赖的是产品入口而不是接口。对企业来说,真正稳妥的做法是把模型当作可替换组件,建立多模型评估、灰度迁移和异常回退机制。
从行业视角看,旧模型退场还有一个信号:大厂正在把计算资源和用户注意力集中到更能变现、更能承接 Agent 的模型线上。未来模型发布不只是技术秀,也会伴随旧能力下线、价格调整、产品入口迁移和生态重新分配。谁能让用户平滑迁移,谁就能在模型快速更替中留住信任。
价格重新算账
与模型退役同时出现的,是 AI 服务价格体系的重新计算。独立开发者 Simon Willison 的测算指出,OpenAI 的调整相对直接,而 Anthropic 则被认为通过 tokenizer 变化让实际使用成本上升。无论具体机制如何,用户能感受到的结果很明确:过去看起来很划算的包月模式,正在被更细、更动态的成本结构取代。
这背后的逻辑并不难理解。大模型使用量持续增长,代码智能体、长上下文、多 Agent 协作和多模态任务都会显著抬高 token 消耗。对厂商而言,固定包月如果继续覆盖极高强度用户,就很容易出现收入和算力成本倒挂。对重度用户而言,曾经“随便用”的体验开始变成“每一步都要考虑是否值得”。
企业受到的影响更大。很多团队引入 AI 工具时,最初只计算账号订阅费,很少把上下文长度、调用频率、失败重试、并行 Agent、文件处理和工具调用成本拆开看。等到 AI 从个人助手变成团队工作流后,账单会突然变得难以预测。尤其是代码 Agent,一次大型重构、一次仓库扫描、一次多轮调试,都可能消耗大量 token。
因此,AI 成本治理会变成企业落地的新基本功。团队需要知道哪些任务适合强模型,哪些任务可以交给轻量模型;哪些流程必须保留长上下文,哪些可以通过摘要、缓存和检索降低消耗;哪些 Agent 允许自动执行,哪些必须限制轮次和权限。模型越来越强之后,真正拉开差距的未必是谁用得最多,而是谁用得更稳定、更可控、更划算。
Agent进入业务
美团正式上线 GEO 营销系统,是 AI 从模型能力走向业务系统的典型案例。它不是单纯给商家一个聊天助手,而是围绕 AI 搜索曝光、本地商家经营、跑腿 Skill 接口和开源能力做组合。AI 经营助手已服务 180 万本地商家,这个规模说明,AI 应用的竞争已经进入真实业务场景:商家要的不是概念,而是曝光、转化、履约和经营效率。
GEO 营销的核心变化在于,商家需要适应“用户通过 AI 找服务”的新入口。过去商家做搜索优化,主要围绕关键词、地图排名、评价和广告投放;现在 AI 搜索开始把用户意图、上下文和推荐理由整合在一起,商家能否被 AI 正确理解、正确推荐,可能影响新的流量分配。这对本地生活平台很关键,因为餐饮、酒旅、跑腿、到店服务本来就高度依赖即时决策。
阿里 Qoder 推出 Cloud Agents,同样说明 Agent 正在往企业可用形态靠近。全托管 Agent 运行平台把开发、部署、运行和管理流程打包,号称可将上线时间从 1 个月缩短到 1 天。这个方向击中了企业痛点:很多公司并不缺模型调用能力,缺的是把 Agent 安全、稳定、低门槛地接进内部流程的工程底座。
阿里云百炼 CLI 开源,则把开发者入口进一步前移。只需一行命令即可接入百炼 150 多款模型及相关能力,并支持多款主流 Agent 框架。对开发者来说,CLI 的价值不只是省几步配置,而是把模型、工具和本地开发流程连接起来。未来 Agent 平台的竞争,会越来越像云服务竞争:谁的接入门槛低、生态兼容好、运行稳定、计费清晰,谁就更容易进入企业工具链。
训练评测补课
Agent 真要进入业务,训练数据和评测体系就必须跟上。中国人民大学与至知研究院开源 ClawGym,提供面向 Claw Agents 的一体化框架,包含 13.5K 任务数据集、训练方案和 200 任务评测基准。它关注的不是模型会不会聊天,而是能不能在真实工作区完成任务,这正是 Agent 落地最难的一段。
过去很多大模型评测偏向问答、数学、代码片段和知识理解,但真实工作流更加混乱。一个 Agent 可能需要读文件、改配置、查日志、调用工具、处理错误、回滚方案、生成报告,还要在权限和上下文限制下保持稳定。单纯看模型基准分数,很难判断它能否在真实环境中完成闭环。ClawGym 这类框架的意义就在于,把“会说”推向“会做”。
这也解释了为什么云厂商和模型公司都在争夺 Agent 基础设施。模型能力只是第一层,后面还需要任务数据、执行环境、评测基准、工具协议、权限模型和可观察性。没有这些底座,Agent 很容易在演示里惊艳,在生产里翻车。企业一旦把 Agent 接进代码仓库、客服系统、营销后台或财务流程,就必须知道它什么时候成功、什么时候失败、失败后如何恢复。
训练和评测补课还会改变人才结构。以后企业需要的不只是提示词使用者,也需要能拆任务、建评测、设权限、做监控、管成本的人。AI Native 组织不是全员无脑调用模型,而是把模型能力嵌入流程,并用工程方法约束风险。Agent 时代的竞争,终究会落到组织能力上。
入口继续分化
除了企业和开发者工具,AI 入口也在继续分化。曾经被市场验证失败的 AI 吊坠、随身穿戴硬件形态,又被 Meta、苹果、OpenAI 重新开发。它们想解决的问题很直接:手机和电脑并不是 AI 的唯一入口,如果 AI 要成为随时在线的助手,就需要更贴近身体、环境和真实活动的设备形态。
不过,随身 AI 硬件并不会因为大厂入场就自动成功。上一轮失败已经说明,用户并不愿意为了“多一个聊天入口”额外佩戴设备。新一代产品必须回答几个问题:它能否比手机更方便?能否提供实时感知和低延迟反馈?能否保护隐私?能否把语音、视觉、位置和个人记忆整合成真正有用的场景?如果答案仍然停留在录音、摘要和聊天,那复活的只是概念,不是需求。
Heygo.ai 的 AI 滑雪穿戴硬件提供了另一个思路:与其做万能入口,不如先切入具体运动场景。它可分析百余种动作指标,提供实时指导和个性化训练方案,并已完成两轮千万级融资。滑雪这种高门槛运动天然需要动作反馈、风险提示和训练建议,AI 硬件如果能把传感器数据转化为可执行建议,就比泛泛的随身助手更容易证明价值。
这说明 AI 应用接下来会出现两条路线:一条是平台型入口,把 AI 放进操作系统、办公软件、云服务和本地生活;另一条是垂直型入口,把 AI 放进运动、健康、教育、陪伴、工业和机器人。前者拼生态和分发,后者拼场景理解和硬件体验。真正能留下来的产品,必须让用户觉得“没有它这件事就不好完成”。
开发文化拉扯
在 AI 代码生成越来越热的同时,开源编程语言 Zig 明确禁止提交任何 AI 辅助生成的代码,目前仍有 200 个未处理 pull request。QEMU、NetBSD、OBS Studio 等项目也采取类似政策。这并不是简单的保守,而是开源社区对代码来源、版权、可维护性和责任边界的警惕。
AI 代码工具降低了开发门槛,也放大了审核压力。项目维护者面对的不是“代码能不能跑”这么简单,还要判断代码是否理解了项目设计、是否引入隐蔽漏洞、是否来自不清晰版权来源、提交者能否长期维护。对大型开源项目来说,一段看似正确的 AI 代码,如果没人真正理解,后续维护成本可能远高于当下节省的时间。
这和企业采用 Agent 的问题本质相同:AI 可以提高生产速度,但不能替代责任链。代码、营销、客服、运营、科研和硬件控制都需要人类定义边界、验证结果、承担后果。越是强大的工具,越需要清晰规范。Zig 的强硬态度未必会成为所有项目的标准,但它提醒行业:AI 生成内容进入关键系统时,透明度和可审计性不能缺席。
未来更可能出现分层治理。一些低风险项目会大量接受 AI 辅助代码,一些基础设施项目会要求明确标注、人工解释和更严格测试,还有一些核心组件会继续禁止或限制。AI 编程不会倒退,但开发文化会重新寻找平衡点:效率要提升,质量、版权和责任也不能被效率吞掉。
竞争回到系统能力
把这些消息放在一起,AI 行业的主线已经很清楚:模型继续迭代,但竞争焦点正在回到系统能力。OpenAI 退役旧模型,是生命周期管理;Anthropic 包月折扣争议,是成本和商业模式重构;美团、阿里把 Agent 推进业务和开发者工具,是场景落地;ClawGym 开源,是训练评测补课;随身硬件和垂直设备升温,是入口探索;Zig 拒绝 AI 代码,则是治理边界的提醒。
对企业用户来说,这些变化意味着选型方式要变。不能只问“哪个模型最强”,还要问它是否稳定、是否可替换、是否容易接入现有系统、成本是否可预测、权限和审计是否完整、出现问题能否回滚。AI 项目越接近生产环境,越不能只靠热情和演示推进,而要像部署数据库、云服务和安全系统一样认真设计。
对个人用户来说,AI 工具也会从“尝鲜”变成“工作习惯”。模型更替会影响日常体验,价格调整会影响使用强度,Agent 工具会改变处理任务的方式,硬件入口会尝试进入运动和生活。用户真正需要培养的不是记住某个模型名称,而是判断什么任务适合交给 AI、结果如何验证、隐私如何保护、成本是否值得。
这轮行业变化没有停在单点突破,而是在模型、价格、Agent、硬件、开源文化之间同时展开。AI 竞争越往后走,越像一场综合工程:谁能把能力、成本、入口、场景和治理一起做好,谁才可能把模型优势变成真正的生产力。









