
为什么缓存会成为高并发网站的关键层
很多网站一开始访问量不大,所有请求直接查数据库也能跑得起来。但当页面访问、搜索、接口调用和后台任务同时增多时,数据库就会逐渐成为最容易被打满的环节。Redis 这类内存缓存的作用,就是把一部分高频读取的数据提前放到更快的位置,让大量请求不必每次都落到数据库。
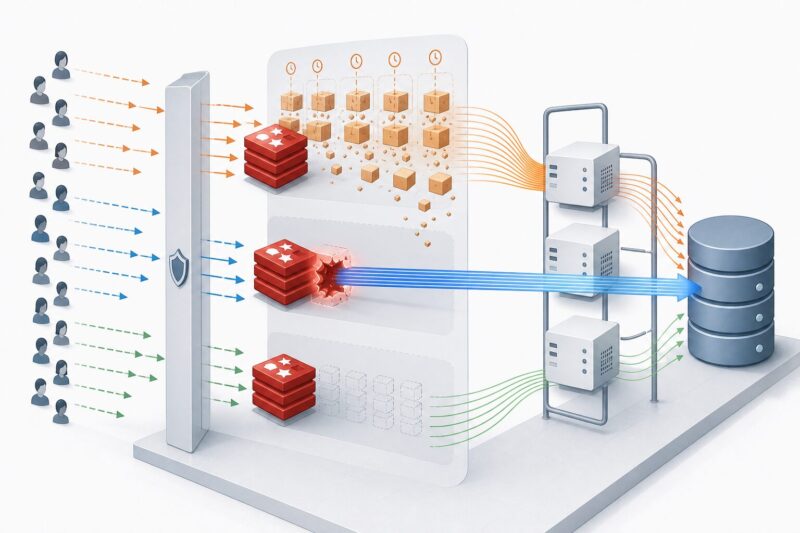
缓存并不是简单地“加一层 Redis”就万事大吉。它更像网站架构里的缓冲区:设计得好,可以显著降低数据库压力;设计得不好,反而会在某个时间点把压力集中释放,导致数据库、应用服务、队列和负载均衡一起抖动。运维排障时常听到的缓存雪崩、缓存击穿、缓存穿透,讲的就是三类典型缓存故障。
这三个概念听起来相似,本质区别在于“哪些请求没有命中缓存”。缓存雪崩是大量缓存同时失效;缓存击穿是某一个热点 Key 突然失效;缓存穿透则是请求的数据本来就不存在,缓存和数据库都挡不住。把这个区别搞清楚,后面的优化思路就会清晰很多。
缓存雪崩:大量 Key 同时失效
缓存雪崩最常见的场景,是很多缓存数据设置了相同或接近的过期时间。例如某个站点在凌晨批量预热商品、文章、配置或排行榜缓存,并统一设置 24 小时过期。到了第二天同一时间,这批 Key 同时失效,大量请求瞬间绕过 Redis 直奔数据库,数据库连接数、慢查询和 CPU 使用率就可能迅速升高。
雪崩也可能来自 Redis 节点故障、网络抖动、配置错误或缓存服务重启。只要缓存层在短时间内大面积不可用,后端数据库就会承受原本由缓存吸收的全部读流量。对于动态页面多、接口调用频繁的网站来说,这种冲击往往比单个慢 SQL 更危险。
预防雪崩的第一步,是不要让大量 Key 使用完全相同的过期时间。可以在基础过期时间上增加随机偏移,例如 30 分钟基础有效期再随机增加 0 到 10 分钟,让失效时间自然分散。第二步,是给核心数据做主动预热和后台续期,在访问高峰前提前刷新热点内容,而不是等用户请求触发重建。
更稳妥的架构还会引入多级保护:本地缓存兜底、限流、熔断、降级页面、只读副本以及队列削峰。对于企业官网、活动页或下载页,如果只是少量静态内容,也可以结合 CDN 缓存和静态化页面,把压力尽量挡在应用服务器之前。
缓存击穿:一个热点 Key 突然失效
缓存击穿关注的是“单个热点 Key”。例如首页推荐列表、热门文章详情、秒杀商品库存、登录配置或某个爆款活动页面,平时访问量非常集中,只要缓存存在,数据库压力并不明显。但如果这个 Key 在高峰期刚好过期,成千上万的请求可能同时发现缓存不存在,然后一起去数据库查询并尝试重建缓存。
击穿和雪崩的区别在于影响范围。雪崩是很多 Key 同时失效,像一片缓存区域塌了;击穿是一个特别热的 Key 被打穿,像某个点被流量钻开了洞。实际排障时,如果数据库慢查询集中在某一条记录或某一类接口上,就要怀疑是不是热点 Key 缓存失效。
处理击穿常用的办法是互斥锁或单飞机制。也就是说,当热点缓存失效时,只允许一个请求去数据库查询并重建缓存,其他请求短暂等待、返回旧值或走降级逻辑。这样可以避免同一时刻大量请求重复查数据库。对特别关键的热点数据,也可以设置逻辑过期:Redis 中的数据不过物理删除,而是在值里记录过期时间,过期后由后台线程异步刷新,前端请求继续拿到旧数据。
还有一种简单做法,是对极少数确定的热点 Key 设置较长有效期,甚至不设置自动过期,而是由数据变更事件主动更新缓存。但这种方式要谨慎,必须保证更新链路可靠,否则容易出现缓存长期不一致的问题。
缓存穿透:请求的数据根本不存在
缓存穿透和前两者不同,它不是缓存刚好失效,而是请求的数据本来就不存在。例如有人不断请求数据库中不存在的用户 ID、文章 ID、订单号或随机字符串。因为缓存里没有,数据库也查不到,如果系统不做处理,每次请求都会穿过缓存直接查数据库。
少量穿透请求在业务里很正常,比如用户访问了一个已删除页面。但如果被爬虫、攻击脚本或错误客户端放大,就会变成持续的数据库压力。它的典型表现是缓存命中率下降,数据库出现大量返回空结果的查询,接口日志里有很多明显异常的参数。
应对穿透,最基础的方法是缓存空值。比如数据库查不到某个文章 ID,就在 Redis 里写入一个短期空结果,后续同样请求直接返回不存在,不再重复打数据库。空值缓存的时间不宜太长,否则新数据刚创建时可能短暂读不到;也不能太短,否则拦截效果不明显。
对于明显非法的参数,可以在进入缓存和数据库之前先做校验。例如 ID 必须是正整数、长度不能异常、枚举值必须在允许范围内。更大规模的系统还会使用布隆过滤器,把“可能存在的 ID 集合”提前放在内存结构中,不在集合里的请求直接拒绝,减少无意义查询。
排查时先看缓存命中率和数据库压力
当网站突然变慢,不要只盯着应用代码。缓存相关问题通常会同时反映在几个指标上:Redis 命中率下降、数据库 QPS 上升、慢查询增加、连接池耗尽、接口响应时间变长。如果这些变化在同一时间出现,就要把缓存层纳入排查范围。
可以先看故障发生时间点是否有批量缓存过期、发布上线、Redis 重启、配置变更或定时任务执行。再结合接口日志,确认是大量不同 Key 失效,还是某个热点 Key 被集中访问,或者是异常参数导致大量不存在数据查询。不要一上来就盲目扩数据库配置,先分清故障类型,处理才会有效。
在服务器资源层面,也要关注 Redis 内存使用率、淘汰策略、网络延迟和连接数。如果内存不足导致 Key 被频繁淘汰,看起来也会像缓存命中率异常下降。应用侧则要检查超时时间、重试策略和连接池配置,避免 Redis 短暂抖动时请求堆积。
实际架构中怎样做更稳
稳定的缓存架构不是只靠一个技巧,而是多层组合。普通数据可以设置随机过期时间,热点数据采用逻辑过期或主动刷新,不存在的数据缓存短期空值,非法请求提前拦截。再配合限流、熔断和降级,即使缓存层发生波动,也不会把全部压力一次性推给数据库。
如果网站规模不大,没必要一开始就把架构做得特别复杂。可以先从三件事做起:给缓存过期时间增加随机值;为核心热点接口加互斥重建;对空结果设置短期缓存。等访问量和业务复杂度上来之后,再逐步加入监控、布隆过滤器、多级缓存和自动预热。
对于部署在云服务器上的中小型网站,缓存稳定性还取决于基础环境。Redis、数据库和 Web 服务如果都放在同一台资源紧张的机器上,一次流量高峰就可能互相抢 CPU、内存和磁盘 IO。使用速维云云服务器时,可以根据业务阶段选择更合适的 CPU、内存和带宽配置,把 Redis 与数据库逐步拆分到不同实例,减少单点资源竞争。
如果业务主要面向海外用户或跨地区访问,也要注意缓存节点和数据库之间的网络延迟。缓存命中可以减少数据库查询,但如果应用服务器、Redis 和数据库距离过远,仍然会增加接口响应时间。规划架构时,应尽量让核心服务处在网络延迟可控的区域,并通过监控持续观察真实访问表现。
小结
缓存雪崩、击穿和穿透的共同点,都是请求没有被缓存层有效挡住;不同点在于失效范围和请求对象。雪崩是大量 Key 同时失效,击穿是热点 Key 被打穿,穿透是不存在的数据反复打到数据库。
理解这三个概念后,缓存优化就不再是背术语,而是能对应到具体动作:分散过期时间、热点互斥重建、空值缓存、参数校验、布隆过滤器、限流降级和监控告警。对网站运维来说,缓存不是越多越好,而是要让它在高峰、异常和故障场景下都能稳稳接住流量。











